

Écrit par
n8n est devenu en 2026 la plateforme de référence pour créer un agent IA sans coder en Python ni gérer un runtime LangChain. Avec son nœud AI Agent introduit en août 2024 et largement enrichi depuis, vous pouvez bâtir un agent autonome qui raisonne, appelle des outils, garde de la mémoire et boucle jusqu’à accomplir sa tâche, le tout dans une interface visuelle drag-and-drop. Ce tutoriel n8n vous accompagne pas à pas dans la création de votre premier agent fonctionnel, avec les bonnes pratiques pour qu’il tienne en production.
Cet article s’inscrit dans notre série sur les plateformes no-code et complète notre comparatif des plateformes no-code agents IA ainsi que notre analyse de LangChain en entreprise, puisque n8n s’appuie nativement sur LangChain.
En bref
- Le nœud AI Agent de n8n est un wrapper autour d’un LLM qui apporte raisonnement ReAct, sélection d’outils, mémoire et output parsing structuré, le tout en visuel.
- n8n 2.0 (janvier 2026) intègre nativement LangChain, 70+ nœuds IA, mémoire d’agent persistante et support des LLM self-hosted.
- Quatre composants minimum pour un agent fonctionnel : trigger, AI Agent node, modèle LLM, mémoire et tools.
- Cas public documenté : SanctifAI a construit son premier workflow agent IA n8n en 2 heures, soit 3 fois plus vite qu’avec Python LangChain.
- Pricing : 20 dollars par mois pour le plan Starter cloud, gratuit en self-hosted (vous payez votre infrastructure).
- Pour aller plus loin et industrialiser votre déploiement, Proactive Academy propose une formation aux agents IA no-code et n8n en entreprise.
Avant de plonger dans le tutoriel, comprenons pourquoi n8n est devenu un choix sérieux pour les agents IA, pas seulement pour l’automatisation classique.
L’intégration LangChain native change la donne. Au lieu d’écrire du code Python LangChain, vous configurez les mêmes concepts (agents, tools, memory, models) sous forme de nœuds visuels. Selon Techsy (avril 2026), « si vous évaluez différents frameworks agent comme LangGraph, CrewAI ou l’OpenAI Agents SDK, n8n se situe dans une catégorie différente : il s’adresse aux gens qui veulent des agents en production sans gérer un runtime Python ».
Les chiffres officiels parlent. n8n 2.0 sorti en janvier 2026 a introduit l’intégration LangChain native, plus de 70 nœuds IA, la mémoire d’agent persistante et le support des LLM self-hosted. Le KW de recherche France atteint 6 600 par mois, le plus haut du marché no-code agent IA.
Le cas SanctifAI illustre le gain de productivité. Selon n8n officiel, « après avoir rejeté les outils LangChain moins flexibles, SanctifAI a sorti son premier workflow n8n en seulement 2 heures, grâce au visual builder et aux systèmes de routage. C’est 3 fois plus rapide qu’écrire des contrôles Python pour LangChain. L’UI visuelle de n8n a éliminé les contraintes de talents engineering rares et de budget. SanctifAI forme désormais ses product managers à construire et tester directement ».
Cette équation 3 fois plus rapide vs Python LangChain est ce qui fait basculer beaucoup d’organisations vers n8n quand elles veulent passer du PoC à la production.
Tout agent n8n suit la même structure hiérarchique. Comprenez-la avant de construire, vous gagnerez du temps.
Le Trigger node déclenche l’exécution. Manual Trigger pour les tests, Chat Trigger pour une interface conversationnelle, Webhook pour intégration avec d’autres systèmes, Gmail Trigger pour réagir aux emails entrants, Schedule Trigger pour exécution périodique. Le choix du trigger dépend de votre cas d’usage.
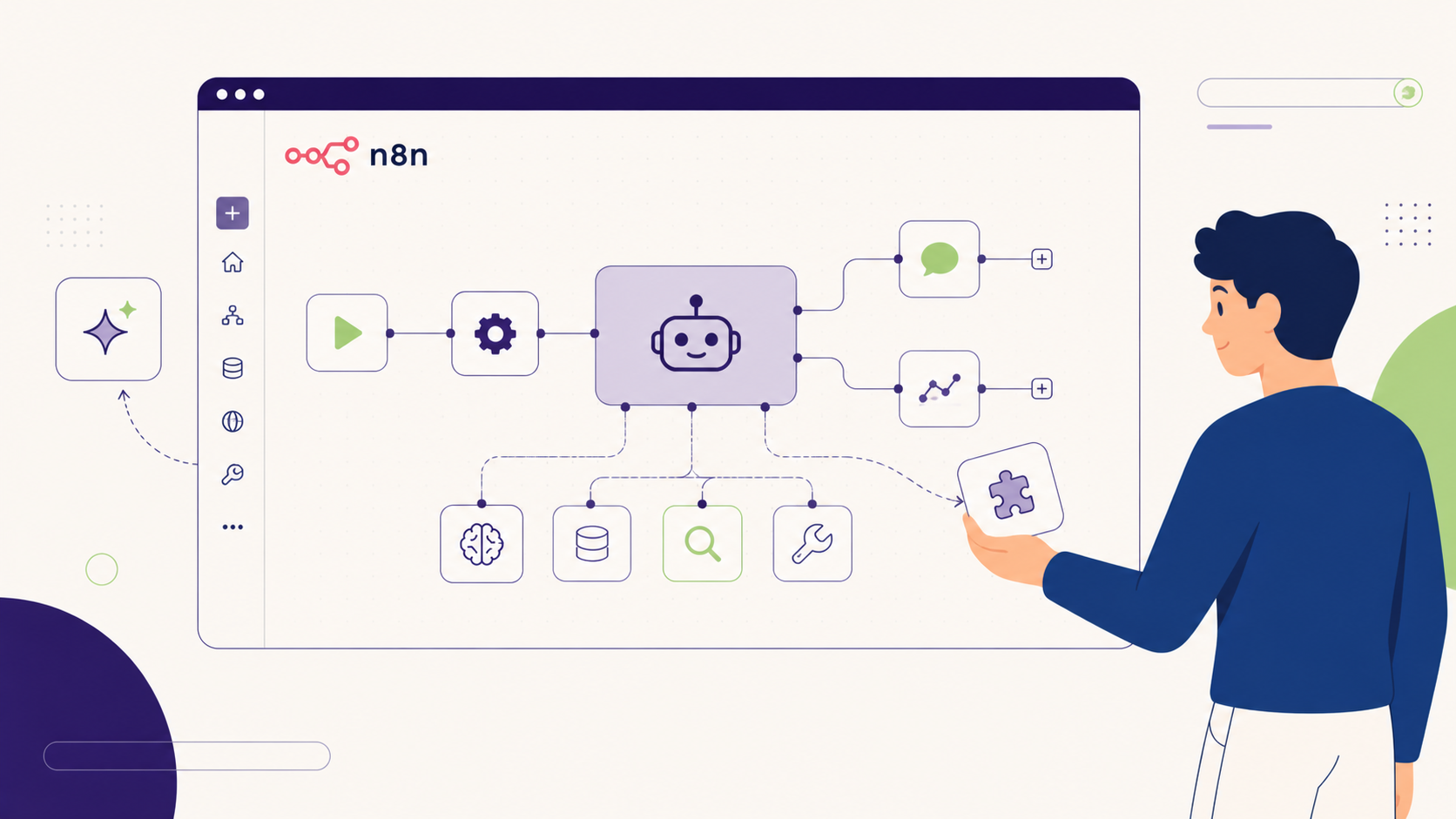
Le nœud AI Agent est le cœur du système. C’est lui qui orchestre la boucle de raisonnement. Selon AI Tool Discovery (avril 2026), il fonctionne sur le pattern ReAct : « le modèle produit une Pensée, sélectionne une Action (un outil), observe le Résultat de l’Action, et répète jusqu’à avoir assez d’information pour produire une Réponse Finale ». Cette boucle tourne automatiquement à l’intérieur du nœud, vous n’avez pas à la câbler manuellement.
Les sub-nœuds se branchent sous le AI Agent et lui donnent ses capacités :
Les Output nodes récupèrent la réponse de l’agent et la routent vers le système aval (envoi email, écriture base de données, post Slack, mise à jour CRM, etc.).
Cette architecture est cohérente sur tous les agents n8n que vous construirez. Une fois comprise, vous pouvez créer 80 % des cas d’usage en variant simplement les briques.
Trois éléments à régler avant d’ouvrir n8n.
Une instance n8n. Deux options : le plan Cloud Starter à 20 dollars par mois (le plus simple pour débuter), ou le self-hosted gratuit via Docker (vous payez votre serveur, environ 5 à 15 euros par mois sur OVH ou Scaleway pour un usage léger). Pour un premier agent de test, le plan Cloud est recommandé. Pour un déploiement enterprise avec contraintes RGPD, le self-hosted sur infrastructure souveraine devient le bon choix.
Une clé API LLM. OpenAI (GPT-5.5-mini est le bon défaut en 2026 selon plusieurs retours production), Anthropic (Claude Sonnet 4.6 pour les agents qui chaînent plusieurs outils), ou Google Gemini. Vous pouvez aussi utiliser Ollama pour des modèles locaux gratuits, mais les performances de tool-calling varient.
Optionnellement, une clé API outil. SerpAPI pour la recherche web (50 dollars par mois) ou Brave Search API qui propose un tier gratuit. Vous pouvez construire des agents sans recherche web, mais c’est l’outil le plus fréquent pour un premier agent.
Une fois ces trois éléments en place, ouvrez votre n8n (sur le cloud ou en local sur http://localhost:5678 si self-hosted) et créez un nouveau workflow.
Nous allons construire un agent de recherche web qui prend un sujet en entrée, cherche sur le web, lit les résultats et produit un résumé structuré. C’est le « hello world » des agents n8n et la base de 80 % des cas d’usage métier.
Voici à quoi ressemblera votre canvas n8n une fois le tutoriel terminé :
Cliquez sur « New Workflow » et nommez-le « Agent de recherche web ». Ajoutez un nœud Manual Trigger (ou Chat Trigger si vous voulez une interface chat). Le Manual Trigger permet de tester le workflow en cliquant sur « Test Workflow » sans déclenchement externe.
Cliquez sur le « + » après le trigger, cherchez « AI Agent » et sélectionnez-le. Le nœud se présente avec 4 slots de connexion (Chat Model, Memory, Tools, Output) qu’il faudra remplir un à un dans les étapes suivantes.
Dans les paramètres du nœud, configurez :
System Message (le rôle et les instructions de l’agent) :
Vous êtes un assistant de recherche. Quand un sujet vous est donné, cherchez sur le web
des informations récentes et fiables, lisez les pages les plus utiles, et fournissez
un résumé structuré avec :
1. Une vue d'ensemble du sujet en 2-3 phrases
2. 3-5 points clés ou données chiffrées
3. Les sources utilisées
Citez toujours vos sources avec leurs URLs. Soyez précis et factuel. N'incluez pas
d'informations que vous n'avez pas trouvées dans les résultats de recherche.Le System Message est central : c’est là que vous définissez le comportement, le ton et les contraintes de votre agent. Plus il est précis, plus l’agent sera fiable.
Sous le nœud AI Agent, cliquez sur le slot « Chat Model » et ajoutez un sub-node OpenAI Chat Model (ou Anthropic, ou Ollama selon votre choix).
Configurez votre clé API (Settings > Credentials > New Credential). Sélectionnez le modèle : gpt-5.5-mini est le défaut recommandé en 2026 selon RoboRhythms (mai 2026) : « le coût par exécution est assez bas pour qu’un agent à 500 exécutions par jour coûte moins de 10 dollars par mois ». Pour des agents qui chaînent 3 ou 4 outils par boucle, Claude Sonnet 4.6 est plus fiable.
Cliquez sur le slot « Memory » et ajoutez un sub-node Window Buffer Memory. C’est l’option la plus simple : elle garde les N derniers messages. Réglez la fenêtre à 5 messages pour démarrer.
Pour un agent de support client en production, préférez Postgres Chat Memory : la mémoire persiste entre les redémarrages serveur et chaque conversation utilisateur reste séparée via un session ID.
C’est ici que votre agent acquiert ses capacités. Cliquez sur le slot « Tools » et ajoutez :
Un outil de recherche web. Cherchez « SerpAPI » ou « Brave Search » dans la liste des tools. Configurez votre clé API. Renseignez la description précisément :
Description : Utilisez cet outil pour rechercher des informations sur le web.
Fournissez une requête de recherche claire et spécifique. Retourne les 5 premiers
résultats avec titre, URL et extrait.Un outil de lecture de page web. Ajoutez un nœud HTTP Request Tool. Description :
Description : Utilisez cet outil pour récupérer et lire le contenu d'une page web.
Fournissez l'URL complète. Retourne le contenu textuel de la page.Selon Aman Singh sur Medium (janvier 2026), « cette description compte plus que vous ne le pensez. Votre agent la lit pour décider quand utiliser cet outil. Des descriptions vagues mènent à des agents confus qui n’appellent jamais la bonne capacité ». C’est un des points qui distingue un agent qui marche d’un agent qui patauge.
Cliquez sur « Test Workflow ». Dans le panneau d’input, entrez un sujet de recherche : « Adoption des agents IA dans les ETI françaises en 2026 ». Lancez l’exécution.
Vous devriez voir l’agent : appeler son outil de recherche web, recevoir des résultats, sélectionner les pages pertinentes, appeler l’outil HTTP Request pour les lire, synthétiser et produire le résumé structuré. La traçabilité visuelle de chaque étape dans n8n est un de ses gros atouts en debug.
Votre premier agent fonctionne en démo. Le faire tourner de manière fiable en production demande quelques disciplines. Selon RoboRhythms (mai 2026), « les builds fragiles sautent la branche d’erreur et utilisent des modèles qui leakent leurs thinking tokens ».
Voici la différence visuelle entre un workflow PoC et un workflow production-ready :
Branche d’erreur systématique. Tout agent en production doit avoir une route d’erreur explicite. Ajoutez une connexion d’erreur sortant du nœud AI Agent vers un nœud d’alerte (Slack, email, log dans Google Sheets). Sans ça, vos échecs silencieux ne seront détectés qu’après plusieurs jours.
Choix du modèle réfléchi. Évitez les modèles avec thinking tokens (certains modèles Ollama locaux) pour les flux qui utilisent un output parser : ils encadrent leur JSON dans des blocs <think> que le parser ne sait pas lire, et le run produit un objet vide silencieusement. Préférez GPT-5.5-mini ou Claude Sonnet 4.6 pour la production.
Descriptions de tools précises. Le modèle décide quel outil appeler en lisant la description. Vague = appel vague. Précis = appel précis. Investissez du temps sur les descriptions, c’est le facteur n°1 de fiabilité d’un agent multi-tools.
Limites explicites pour contrôler les coûts. Le nœud AI Agent expose un paramètre Max Iterations : limitez-le à 5 ou 10 selon votre cas. Un agent qui boucle 20 fois sur le même problème coûte cher et produit rarement mieux qu’un agent qui s’arrête à 5 itérations.
Logging systématique. Utilisez l’historique d’exécution natif de n8n ou pipez les sorties dans un Google Sheets pour revue hebdomadaire. Détectez les misclassifications tôt avant qu’elles ne deviennent un problème de qualité visible par vos utilisateurs.
Versioning des workflows. n8n 2.0 introduit un mode draft qui empêche les modifications de passer en production sans publication explicite. Utilisez-le. Pour des modifications critiques, exportez votre workflow en JSON et conservez les versions dans un git interne.
Une fois votre premier agent maîtrisé, voici les trois patterns qui couvrent la majorité des besoins métier que nous voyons en formation.
Pattern 1 : Triage d’emails entrants. Trigger Gmail, AI Agent avec system message décrivant les catégories, tools pour rechercher dans l’historique du client (Gmail Search, Airtable lookup), output qui route vers Slack ou crée un ticket. Le cas le plus fréquent en support client B2B.
Pattern 2 : Agent de support avec base de connaissances. Chat Trigger, AI Agent avec memory persistante, tool Pinecone ou Supabase Vector Store qui interroge votre knowledge base interne, fallback vers escalade humaine via Slack quand l’agent ne trouve pas la réponse. C’est le cas qui demande de combiner n8n avec une couche RAG, voir notre analyse de LlamaIndex et du RAG pour la dimension données.
Pattern 3 : Agent de prospection. Schedule Trigger qui se déclenche tous les matins, lit une liste de prospects depuis Google Sheets, AI Agent avec tools Tavily ou Perplexity pour rechercher chaque prospect, écrit un email personnalisé en draft Gmail. Cas typique des équipes commerciales B2B qui veulent industrialiser sans déshumaniser.
Vidéo officielle n8n (20 min, chapitrée) — construction d’un Q&A AI Agent avec base de connaissances.
Soyons honnête sur les limites. n8n est excellent pour 80 % des cas d’usage agent, pas pour tous.
Si vous construisez un produit logiciel commercial où l’agent doit être embarqué dans votre interface utilisateur final avec un contrôle granulaire sur chaque étape de raisonnement, partez sur LangGraph en Python. n8n est parfait pour les workflows métier internes, moins pour les agents intégrés à un produit SaaS.
Si vous avez besoin d’architectures multi-agents très complexes avec hiérarchie supervisor/sub-agents, durable execution avancée, observabilité fine au niveau de chaque token, regardez plutôt LangGraph ou Google ADK. n8n a des capacités multi-agents mais reste plus orienté workflow que pure orchestration agent.
Si la latence est critique sous les 100 millisecondes (chat temps réel à fort volume), n8n ajoute un overhead de framework qui peut être problématique. Pour ces cas, l’appel direct à l’API du LLM avec une couche d’orchestration custom est plus efficace.
Pour la plupart des organisations qui démarrent ou industrialisent leurs premiers agents IA en 2026, ces limites ne s’appliquent pas. n8n reste le choix par défaut intelligent.
L’investissement formation diffère selon les profils.
Le citizen developer métier doit maîtriser l’architecture en 4 composants, les triggers les plus courants pour son domaine, la rédaction de prompts pour le system message, la rédaction de descriptions de tools, le debug visuel. Comptez 2 jours intensifs sur la plateforme + pratique encadrée sur un cas réel de son métier. À l’issue, il sait construire un agent simple à fiable.
Le tech lead ou architecte solutions doit comprendre l’intégration LangChain sous-jacente, les patterns multi-agents, le self-hosting et le scaling, la gestion des credentials, le passage en production avec branches d’erreur et observabilité. Comptez 3 à 5 jours + accompagnement sur les premiers déploiements.
Le DSI doit avoir la grille de décision n8n vs alternatives (Zapier, Make, Dust pour le no-code, ou frameworks code), comprendre les implications self-hosted vs cloud, le pricing à l’échelle, la gouvernance multi-équipes. C’est typiquement le contenu de notre parcours formation aux plateformes d’agents IA pour décideurs, qui couvre n8n parmi les autres options.
L’erreur fréquente : former uniquement le citizen developer sans former le tech lead. Résultat : les agents passent le PoC mais s’effondrent en production faute de gouvernance et de vrais skills opérationnels.
Non. C’est précisément l’argument de n8n. Vous configurez visuellement les concepts LangChain (agents, tools, memory, models) sans écrire de code. Une connaissance générale des LLM et de la logique de workflow est utile, mais le Python n’est pas requis. Pour des transformations de données avancées entre nœuds, un peu de JavaScript devient utile mais reste optionnel.
Pour 1 à 5 agents avec quelques centaines d’exécutions par jour, oui largement. Au-delà de quelques milliers d’exécutions par jour, regardez le plan supérieur ou basculez en self-hosted. Le tier gratuit existe aussi mais avec des limites strictes sur le nombre de workflows actifs.
Pour la plupart des cas, GPT-5.5-mini offre le meilleur rapport coût/performance en 2026 (moins de 10 dollars par mois pour 500 exécutions par jour). Pour les agents complexes qui chaînent 3 à 5 outils par boucle, Claude Sonnet 4.6 est plus fiable. Pour des contraintes de souveraineté forte, Mistral via Ollama self-hosted est l’alternative française.
n8n est sous licence fair-code (sustainable use license), pas strictement open source au sens OSI. Le code est public, vous pouvez self-héberger librement, mais l’usage commercial à grande échelle peut tomber sous des conditions spécifiques. Pour la majorité des usages enterprise classiques (déploiement interne), c’est sans contrainte. Lisez la licence avant de l’embarquer dans un produit commercial.
Pour un agent moyennement utilisé en ETI française (500 à 2 000 exécutions par jour avec GPT-5.5-mini), comptez environ 15 à 30 euros par mois en tokens LLM + 20 dollars par mois pour n8n Cloud, soit moins de 50 euros par mois en frais récurrents. Le coût initial de mise en place (formation + premier agent en production) se situe autour de 5 000 à 12 000 euros selon la complexité.
Oui, c’est même un des ajouts récents les plus utiles. Le MCP Client Tool connecte votre agent n8n à des serveurs MCP externes. Votre agent découvre automatiquement tous les outils que ce serveur expose et peut les appeler. C’est un seul nœud qui peut débloquer des dizaines d’outils externes. Sujet que nous traiterons en profondeur dans notre cluster dédié aux protocoles agents (MCP, A2A) à venir.
n8n propose des programmes de formation officiels et un système de badges. Pour une approche encadrée avec accompagnement de cas d’usage métier réels, une formation externe avec un organisme spécialisé reste plus efficace pour les équipes B2B francophones, surtout quand on combine n8n avec d’autres dimensions (gouvernance, conformité, méthode d’évaluation).
Oui sans problème. Le déploiement Docker est documenté et fonctionne sur tout VPS Linux. Pour une ETI française avec contraintes RGPD, c’est même la voie recommandée : vous gardez le contrôle complet de vos données et de votre infrastructure, avec des coûts qui démarrent à environ 10 euros par mois pour un VPS basique. Comptez quand même un demi-jour de mise en place initiale et de la maintenance régulière des mises à jour.
n8n a transformé en 2026 l’expérience de création d’agents IA pour les organisations qui veulent industrialiser sans tout réécrire en Python. La combinaison de l’intégration LangChain native, du visuel drag-and-drop, des 400+ connecteurs et du self-hosting souverain en fait un outil rare : assez complet pour les vrais cas d’usage production, assez accessible pour que des équipes non-développeurs puissent en tirer parti. Le piège n’est pas dans l’outil lui-même mais dans la croyance que créer un agent en 30 minutes suffit pour le faire tourner 12 mois en production. Les disciplines opérationnelles, la sélection du bon modèle, les descriptions précises des tools, les branches d’erreur, la gouvernance multi-équipes : c’est ce qui distingue les déploiements n8n qui réussissent de ceux qui s’éteignent au bout de 3 mois. Pour structurer cette montée en compétence dans votre organisation, se former à n8n et aux plateformes d’agents IA en entreprise avec Proactive Academy reste le moyen le plus direct de transformer votre premier agent en système qui tient.



Laisser un commentaire