

Écrit par
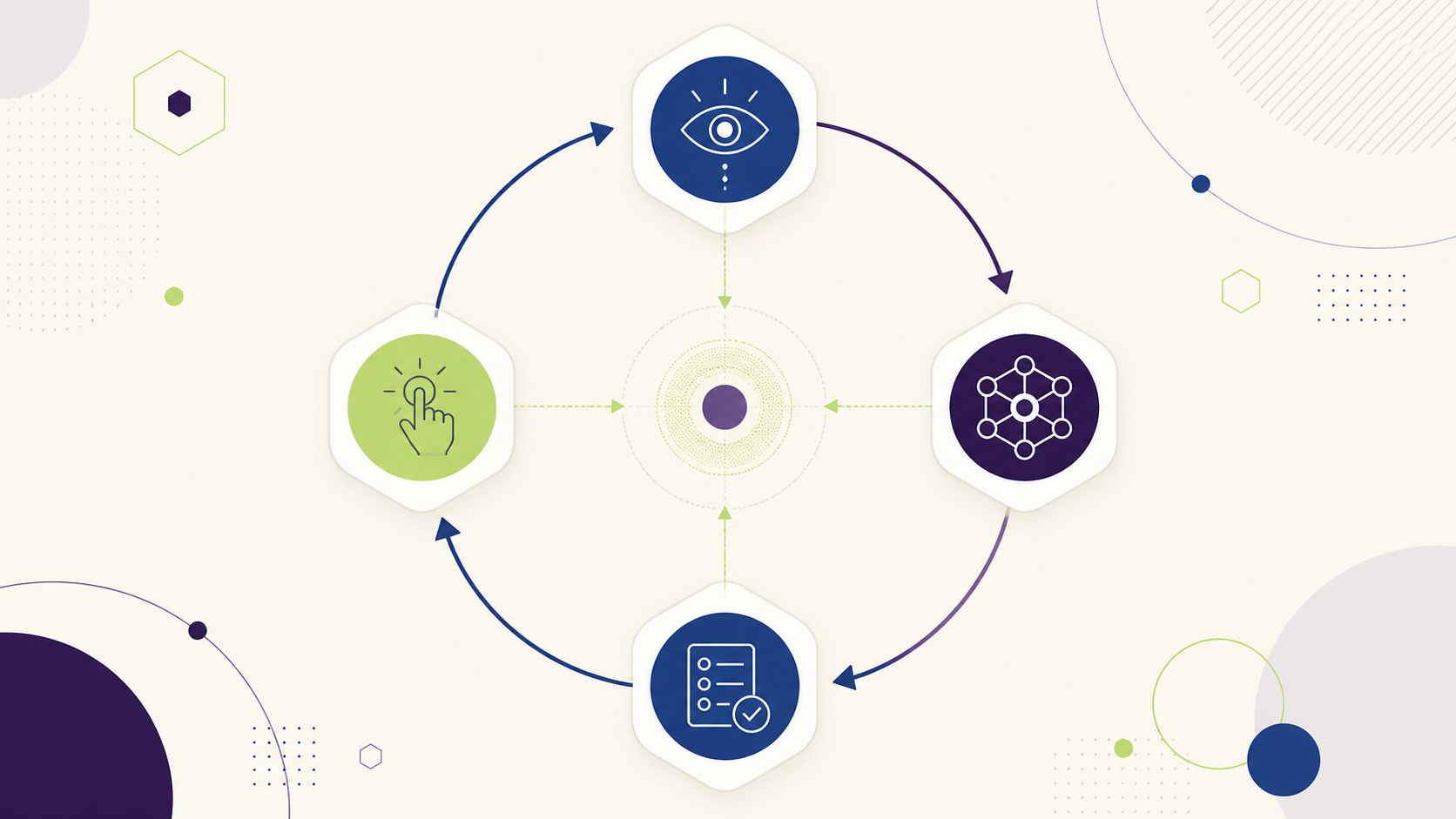
Tout agent IA, quelle que soit sa complexité — du simple bot Slack à l’agent d’entreprise multi-outils — repose sur la même mécanique fondamentale : une boucle perception-raisonnement-action que le système exécute jusqu’à atteindre son objectif. Cet article détaille cette mécanique étape par étape, présente les briques techniques qui la composent, et illustre le tout avec un cas industriel public documenté en 2026.
Cet article fait partie de notre guide complet sur les agents IA, qui pose les fondations du concept et de son écosystème.
En bref
- Un agent IA fonctionne en boucle : il perçoit son environnement, raisonne via un LLM, agit sur des outils externes, mémorise le résultat, et recommence — jusqu’à atteindre l’objectif ou qu’un garde-fou s’active.
- Selon les prévisions de Deloitte reprises par Octoparse (avril 2026), 25 % des entreprises françaises seront en phase pilote d’agents IA fin 2026, mais 78 % citent la qualité des données comme premier frein au déploiement (Adobe Tendances Digitales 2026).
- Pour structurer cette compétence dans vos équipes, Proactive Academy propose une formation aux agents IA en intra et inter, éligible OPCO et CPF.
Tout agent IA suit le même cycle. Il a été formalisé pour la première fois en 2022 dans le pattern ReAct (Reasoning + Acting) et reste aujourd’hui le socle de toutes les architectures agentiques en production.
Comme l’explique Octoparse (avril 2026), la mécanique se déroule en quatre temps qui se répètent en boucle. L’utilisateur fournit un objectif en langage naturel (« Trouve les 10 concurrents de notre produit sur le marché français et résume leur positionnement tarifaire »). L’agent décompose cet objectif en sous-tâches séquentielles, choisit les outils nécessaires à chaque étape, exécute, observe les résultats, et ajuste si besoin.
Cette boucle distingue fondamentalement un agent d’un simple appel à un LLM. Comme le précise la documentation officielle de n8n, « les LLM peuvent sélectionner le meilleur outil pour accomplir une tâche, ou même simuler des prises de décision complexes, mais ils ne peuvent pas agir sur ces décisions ni utiliser les outils par eux-mêmes. Les agents IA ajoutent cette fonctionnalité orientée objectif : ils peuvent utiliser des outils, agir sur leurs résultats, accomplir des tâches et résoudre des problèmes ».
Selon Ayi Nedjimi Consultants (février 2026), un agent IA robuste repose sur quatre piliers fondamentaux qui interagissent en permanence : le LLM backbone (le cerveau), les outils (les mains), la mémoire (la rétention) et le module de planification (la stratégie).
La perception correspond à tout ce que l’agent peut lire ou observer. Comme le décrit Tuto.com (avril 2026), il peut s’agir d’« un email qui arrive, un fichier déposé dans un dossier, une fiche produit sur un site, un message Slack ». Plus largement, les sources de perception en 2026 incluent :
La qualité de la perception conditionne tout le reste. Un agent qui « voit » des données mal structurées ou périmées prendra de mauvaises décisions, quelle que soit la puissance de son LLM. C’est précisément pourquoi 78 % des entreprises françaises citent la qualité et l’intégration des données comme principal frein, selon les données reprises par Octoparse.
Le raisonnement est assuré par un grand modèle de langage qui sert de cerveau. Tuto.com (avril 2026) cite les modèles dominants en 2026 : « GPT-5, Claude Opus 4.7, Gemini 3 ou Mistral Large ». Le LLM analyse la situation, découpe un objectif complexe en sous-tâches, et décide de la prochaine action.
Trois techniques structurent ce raisonnement :
Chain-of-Thought (chaîne de pensée) : le LLM verbalise son raisonnement étape par étape avant de produire une décision, ce qui améliore la qualité et la traçabilité.
ReAct (Reasoning + Acting) : le LLM alterne explicitement raisonnement et action — il pense, agit, observe le résultat, repense, agit à nouveau. C’est le pattern dominant en production en 2026.
Routage multi-modèles : pour optimiser coûts et performances. Comme le recommande Thiga (mars 2026), une architecture mature utilise « un modèle Reasoning (comme GPT-4 et GPT-5-thinking ou Claude Sonnet ou Gemini Pro) pour la planification stratégique, et un modèle plus économique (type Gemini Flash, Claude Haiku, GPT-5-instant) pour les tâches fréquentes comme le résumé ou la rédaction ».
Le critère technique critique pour un usage agent : la fiabilité du function calling. Selon Ayi Nedjimi Consultants (février 2026), « le modèle doit générer des appels de fonction syntaxiquement corrects avec un taux d’erreur inférieur à 2 %. Claude Opus 4, GPT-5 et Gemini 2.5 atteignent ce seuil en production ».
L’action est la capacité de l’agent à utiliser des outils pour produire un effet concret dans le monde réel. Le mécanisme technique sous-jacent s’appelle le function calling ou tool use : le LLM produit un appel structuré à une fonction définie par le développeur, avec ses paramètres.
Concrètement, l’agent peut :
L’écosystème s’est standardisé fin 2024 avec le protocole MCP (Model Context Protocol) lancé par Anthropic, qui permet aux agents de se connecter à des outils externes sans intégration manuelle. En 2026, n8n supporte également MCP nativement selon Tech Insider (mars 2026).
La mémoire permet à l’agent de garder trace de ce qu’il a fait, de ses erreurs passées et des informations utiles. Sans mémoire, comme le souligne Tuto.com (avril 2026), « un agent refait les mêmes fautes en boucle ».
Deux niveaux de mémoire structurent les agents matures :
Mémoire à court terme : la conversation ou la tâche en cours. Elle vit dans la fenêtre de contexte du LLM (entre 200 000 et 2 millions de tokens selon les modèles en 2026). Suffisante pour des tâches isolées, elle disparaît à la fin de la session.
Mémoire à long terme : stockée dans une base externe pour persister au-delà d’une session. Deux technologies dominent : les bases vectorielles (Pinecone, Weaviate, Qdrant) qui permettent la recherche sémantique sur de grands volumes, et les graphes de connaissance qui structurent les relations entre entités.
Les agents enterprise les plus avancés combinent les deux dans une architecture de mémoire augmentée — vectorielle pour la similarité, graphe pour la causalité.
Comme le documente l’agence Mirax dans son retour terrain 2026, un cas industriel concret illustre la boucle PRA en action : la mise à jour automatisée des fiches produits et l’optimisation SEO pour Calixar-Eurofins.
L’objectif assigné à l’agent : maintenir à jour le catalogue produit sur le site, en optimisant chaque fiche pour le SEO, sans surcharger les équipes éditoriales.
Phase de perception : l’agent surveille en continu le PIM (Product Information Management) de Calixar-Eurofins. Dès qu’une fiche produit est créée ou modifiée par un product manager, l’agent capte l’événement.
Phase de raisonnement : le LLM (Claude ou GPT selon la configuration) analyse la fiche, identifie les éléments manquants pour le SEO (méta-description, mots-clés cibles, structure H2/H3, alt text des images), évalue la pertinence sémantique par rapport aux requêtes cibles du marché, et planifie les actions à entreprendre.
Phase d’action : l’agent enrichit automatiquement les balises méta, génère le maillage interne pertinent vers les fiches produits liées, vérifie la cohérence avec le glossaire technique de l’entreprise, publie la version optimisée sur le site, et indexe la nouvelle URL dans la sitemap.
Phase de mémoire : l’agent enregistre les patterns d’optimisation efficaces (quels termes fonctionnent dans tel secteur, quelle structure performe mieux), ce qui améliore les itérations suivantes. Mirax précise aussi que tout est documenté : « logs temps réel, audit de décision, conformité RGPD native — les clients sont capables d’apporter des preuves à la CNIL ou à leur DSI sous 48h ».
Le résultat documenté par Mirax : un volume d’indexation multiplié sans dégradation de la qualité éditoriale, et une isolation VPN de chaque workflow sensible pour la conformité.
C’est exactement la mécanique théorique de la boucle PRA appliquée à un cas industriel mesurable. Et c’est aussi pourquoi ces architectures restent exigeantes à concevoir : chaque phase peut introduire des erreurs en cascade si la conception n’est pas rigoureuse.
Selon AzenFlow (mars 2026), pour une PME française qui démarre, le coût d’un agent IA bâti sur n8n self-hosted oscille entre 5 et 100 euros par mois selon l’usage : n8n auto-hébergé est gratuit, et seules les API LLM (Claude, GPT, Mistral) sont facturées à l’usage.
Le coût augmente avec trois facteurs :
Le volume de tâches traitées : chaque raisonnement consomme des tokens d’API. Selon Tuto.com (avril 2026), « plusieurs milliers de tokens par tâche » sont fréquents pour un agent moyennement complexe.
Le choix des modèles : un agent qui utilise Claude Opus ou GPT-5 sur chaque étape coûte 5 à 10 fois plus cher qu’un agent routé sur Claude Haiku ou Gemini Flash pour les tâches secondaires.
La complexité des intégrations : connecter un CRM, un ERP, plusieurs APIs externes augmente le coût de mise en place initial mais reste linéaire ensuite.
Pour les déploiements enterprise sur Salesforce Agentforce ou Microsoft Copilot Studio, les coûts peuvent atteindre des dizaines à centaines de milliers d’euros sur la première année — un sujet traité dans notre article Combien coûte un agent IA en 2026.
Trois erreurs reviennent systématiquement dans les déploiements ratés :
Erreur 1 — Mal cadrer l’objectif. Un objectif trop large (« gère mes mails ») produit un agent imprévisible. Un objectif trop étroit (« supprime tous les mails de plus de 30 jours ») n’a pas besoin d’IA, un script suffit. Le bon cadrage cible des tâches structurées mais nécessitant du jugement contextuel.
Erreur 2 — Sous-estimer la qualité des données. Comme rappelé plus haut, 78 % des entreprises FR citent la qualité et l’intégration des données comme premier frein selon Adobe via Octoparse. Un agent ne peut pas mieux raisonner que ce que ses données lui permettent de percevoir.
Erreur 3 — Négliger l’observabilité. Plus un agent est autonome, moins on voit ce qu’il fait. Les équipes qui réussissent leurs déploiements tiennent systématiquement des tableaux de bord de trajectoire — qu’a fait l’agent, quand, avec quels outils, quels résultats, quels échecs. Sans observabilité, impossible de détecter les dérives en production.
Concevoir un agent fonctionnel ne s’improvise pas. Il faut comprendre la boucle PRA, choisir les bons modèles selon les tâches, maîtriser le function calling, structurer la mémoire, et concevoir les garde-fous.
Trois compétences sont particulièrement structurantes en 2026 :
Proactive Academy propose un parcours pédagogique sur les agents IA en entreprise qui couvre ces trois dimensions, avec des ateliers pratiques sur n8n et des cas d’usage adaptés à votre secteur. La formation est éligible OPCO et CPF, et inclut un module dédié à la gouvernance et à la conformité AI Act.
Un appel à un LLM produit une réponse ponctuelle à un prompt — c’est une fonction « entrée → sortie » sans état. La boucle PRA ajoute la capacité d’observer le résultat de chaque action, de réajuster, et de continuer jusqu’à atteindre un objectif. C’est ce qui transforme un modèle de langage en système agentique. Pour aller plus loin, lire notre article IA agentique : définition, principes et exemples.
Pas nécessairement. Les plateformes no-code comme n8n (gratuit en self-hosted, 20 €/mois en cloud selon Octoparse), Make ou Zapier AI permettent de bâtir des agents fonctionnels par glisser-déposer. Pour des architectures plus complexes (multi-agents, mémoire avancée, intégrations spécifiques), un développeur Python avec les frameworks LangChain, LangGraph ou CrewAI reste nécessaire.
Pour un cas d’usage simple en no-code (tri d’emails, qualification de leads basique), comptez 1 à 2 semaines incluant le cadrage. Pour un agent enterprise avec intégrations CRM/ERP et garde-fous de conformité, comptez 4 à 12 semaines selon la complexité. Le facteur limitant n’est presque jamais la technique mais la qualité des données disponibles et le cadrage de l’objectif.
Pour une PME française qui démarre, les outils dominants en 2026 sont : n8n (open source, version cloud à 20 €/mois) pour la flexibilité ; Make pour une approche plus clé en main ; OpenClaw pour les organisations qui veulent garder le contrôle total avec MCP natif. Pour les modèles : Claude (Anthropic) excelle sur le suivi d’instructions complexes, GPT est polyvalent et très documenté, Mistral est intéressant pour la souveraineté. Notre article Comparatif des plateformes no-code pour créer un agent IA détaille les forces de chacune.
Pas au sens où il modifierait son LLM sous-jacent — celui-ci reste figé entre deux mises à jour publiées par l’éditeur. Ce qui « apprend » dans un agent, c’est sa mémoire à long terme (vectorielle ou graphe) qui accumule les patterns réussis et les erreurs passées. Combinée à des prompts adaptatifs, cette mémoire fait que l’agent devient plus performant dans le temps — mais ce n’est pas du fine-tuning, c’est de la capitalisation.
Comprendre comment fonctionne un agent IA, c’est se donner les moyens de le concevoir correctement — et d’identifier ce qui le rend fiable ou défaillant en production. La boucle perception-raisonnement-action paraît simple sur le papier, mais sa mise en œuvre exige rigueur, observabilité et compétences spécifiques. Pour structurer cette compréhension dans vos équipes, se former aux agents IA avec Proactive Academy reste le moyen le plus direct de passer de la curiosité technique à la maîtrise opérationnelle.



16 juin 2026
Intelligence Artificielle – IA
16 juin 2026
Intelligence Artificielle – IA
16 juin 2026
Intelligence Artificielle – IA
Laisser un commentaire