

Écrit par
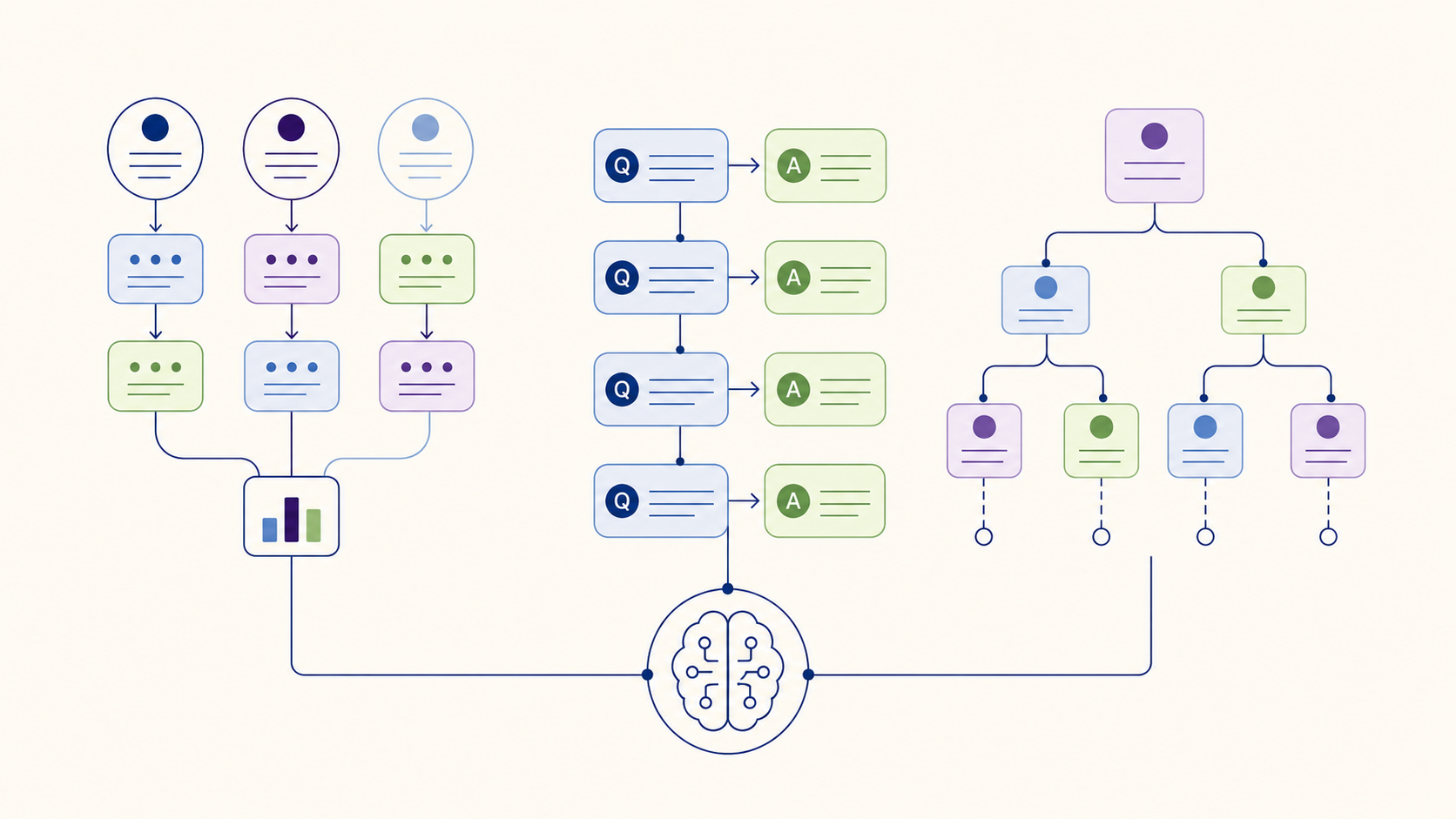
Le Chain-of-Thought publié par Wei et al. en 2022 a ouvert une voie : faire raisonner les grands modèles de langage étape par étape. Mais une chaîne de raisonnement unique reste fragile. Une erreur intermédiaire et toute la suite s’effondre. Entre 2022 et 2023, trois équipes de recherche ont proposé des architectures multi-chain qui dépassent cette limite : Self-Consistency (Wang et al.), Self-Ask (Press et al.) et Tree-of-Thoughts (Yao et al.). Ces techniques transforment le prompt engineering : elles permettent à un modèle d’explorer plusieurs chemins de raisonnement, de comparer les conclusions, et de produire des réponses plus fiables sur les problèmes complexes. Ce guide hub compare les trois architectures et aiguille vers les ressources approfondies pour chacune.
Cet article est un comparatif des techniques avancées de raisonnement. Pour chaque technique en profondeur, voir nos guides dédiés : Self-Consistency, Self-Ask, Tree-of-Thoughts. Pour la base CoT sur laquelle ces techniques s’appuient, voir notre guide Chain-of-Thought.
En bref
- Self-Consistency (Wang et al. 2023) : on échantillonne plusieurs chaînes de raisonnement CoT et on garde la réponse majoritaire. Améliore la fiabilité au prix d’un coût d’inférence multiplié.
- Self-Ask (Press et al. 2022) : on décompose explicitement le problème en sous-questions intermédiaires avant d’y répondre. Particulièrement efficace sur les questions compositionnelles.
- Tree-of-Thoughts (ToT) (Yao et al. 2023) : on explore un arbre de pensées en parallèle, avec évaluation à chaque branche et possibilité de revenir en arrière. État de l’art pour la résolution de problèmes complexes.
- Coût croissant : CoT < Self-Consistency < Self-Ask < ToT en complexité de mise en œuvre et coût d’inférence.
- Règle pratique 2026 : commencez par CoT, passez à Self-Consistency si la fiabilité importe, passez à Self-Ask si le problème est compositionnel, réservez ToT aux problèmes vraiment complexes qui justifient le surcoût.
- Pour structurer la maîtrise de ces techniques dans vos équipes, découvrez notre formation experte au prompt engineering en entreprise.
Le Chain-of-Thought résout de manière spectaculaire les problèmes de raisonnement de complexité moyenne (problèmes mathématiques de niveau école primaire, déductions logiques simples, raisonnements de sens commun). Sur les problèmes vraiment complexes, trois faiblesses du CoT classique apparaissent.
Faiblesse 1 : la fragilité aux erreurs intermédiaires. Sur une chaîne de raisonnement de 5 à 10 étapes, une seule erreur intermédiaire suffit à fausser la réponse finale. Plus la chaîne est longue, plus la probabilité d’erreur cumulée est élevée. Le modèle, qui ne distingue pas une étape juste d’une étape fausse, continue son raisonnement sur des bases erronées.
Faiblesse 2 : l’absence d’auto-évaluation. Le CoT classique produit une chaîne, puis répond. Il n’y a pas de mécanisme pour vérifier si la chaîne tient la route, comparer avec d’autres chaînes possibles, ou revenir en arrière en cas de blocage. Le modèle s’engage dans une direction et ne peut pas la corriger.
Faiblesse 3 : la difficulté sur les questions compositionnelles. Pour une question qui demande de combiner plusieurs faits (« Qui a vécu plus longtemps : Gandhi ou Einstein ? »), le CoT classique mélange souvent les recherches dans une même chaîne, et fait des erreurs factuelles ou de croisement.
Les trois techniques présentées ci-dessous adressent chacune une de ces faiblesses.
Self-Consistency exécute le même prompt CoT plusieurs fois avec une part de hasard (température non nulle), puis garde la réponse majoritaire parmi les sorties. L’intuition : les bonnes réponses convergent par plusieurs chemins, les erreurs divergent dans plusieurs directions. C’est la technique la plus simple à mettre en œuvre des trois.
Coût d’inférence multiplié par le nombre d’échantillons (typiquement 5× à 40×). Particulièrement utile sur les sorties à enjeu où l’erreur coûte cher. Pour le détail complet (mécanisme, nombre d’échantillons optimal, A/B test, combinaisons), voir notre guide Self-Consistency en profondeur.
Self-Ask force le modèle à expliciter les sous-questions intermédiaires avant de répondre à la question principale. La structure parsable (« Sous-question : » / « Réponse intermédiaire : » / « Réponse finale : ») rend les sorties exploitables programmatiquement et auditables humainement.
Particulièrement efficace sur trois familles de problèmes : comparaisons multi-entités, raisonnement temporel multi-événements, inférences compositionnelles à 3 sauts ou plus. Coût d’inférence environ 1,5× CoT classique. Pour le détail complet (gap de compositionnalité, scaffolding, couplage RAG), voir notre guide Self-Ask en profondeur.
Tree-of-Thoughts traite le raisonnement comme une exploration d’arbre où chaque nœud est une « pensée » intermédiaire. À chaque nœud, le modèle génère plusieurs pensées candidates, les évalue, et peut revenir en arrière en cas d’impasse. C’est l’architecture la plus avancée du domaine.
Coût d’inférence 50× à 200× CoT classique. Réservé aux problèmes vraiment complexes (combinatoires, génératifs sous contraintes multiples, diagnostics avec espace d’hypothèses large) où le gain de qualité justifie le surcoût. Implémentation typiquement dans un framework agentique (LangGraph, LangChain) plutôt qu’à la main. Pour le détail complet (mécanisme arbre, BFS/DFS, jeu de 24, framework agentique), voir notre guide Tree-of-Thoughts en profondeur.
| Type de problème | Technique recommandée | Pourquoi |
|---|---|---|
| Tâche courante (rédiger, résumer, classifier) | Zero-shot ou Few-shot (voir hub C13-2) | Pas besoin de raisonnement chaîné |
| Raisonnement linéaire de complexité moyenne | CoT (voir C13-3) | CoT classique suffit |
| Raisonnement critique à fiabiliser | Self-Consistency | Vote majoritaire réduit les erreurs aléatoires |
| Question compositionnelle (comparaison, croisement) | Self-Ask | Décomposition explicite débloque les inférences |
| Problème combinatoire ou exploratoire | Tree-of-Thoughts | Exploration d’arbre avec backtracking |
| Génération créative sous contraintes multiples | Tree-of-Thoughts | Permet de tester plusieurs voies |
| Diagnostic différentiel complexe | Self-Ask + Self-Consistency | Décomposition + vote pour les hypothèses |
Les trois techniques peuvent se combiner. Trois combinaisons utiles en 2026.
Self-Consistency + CoT : la base de la fiabilisation. Vous écrivez un prompt CoT classique, vous l’exécutez 10 à 20 fois avec une température non nulle, et vous prenez la réponse majoritaire. Cette combinaison est la plus rentable pour les usages où la fiabilité prime sur le coût. Voir Self-Consistency en profondeur.
Self-Ask + CoT : pour les questions compositionnelles, vous structurez avec Self-Ask pour décomposer, puis chaque sous-question est traitée en CoT. Cette combinaison stabilise les sorties sur les benchmarks multi-hop. Voir Self-Ask en profondeur.
Tree-of-Thoughts + Self-Consistency : à chaque nœud de l’arbre ToT, on applique Self-Consistency pour évaluer la qualité d’une pensée par échantillonnage. Cette combinaison est extrêmement coûteuse mais donne l’état de l’art sur les problèmes les plus durs. Voir Tree-of-Thoughts en profondeur.
Depuis 2024-2025, les modèles « raisonnants » d’OpenAI (o1, o3), Anthropic (Claude 3.7 et au-delà avec mode extended thinking) et DeepSeek (R1) ont intégré des variantes de ces techniques directement dans l’entraînement et l’inférence. Ces modèles produisent une chaîne de raisonnement interne longue, parfois avec exploration d’alternatives, avant de répondre. L’utilisateur n’a plus besoin d’expliciter Self-Consistency ou ToT : le modèle fait quelque chose de proche en interne.
Pour autant, la maîtrise de ces techniques reste utile en 2026 pour quatre raisons :
Pour creuser chaque technique, nous proposons trois guides spécialisés.
Pour Self-Consistency en profondeur : notre guide Self-Consistency détaille le mécanisme en 3 étapes, le réglage du nombre d’échantillons (plancher 5, plage 10-20, critique 30-40), la méthodologie d’A/B test, 4 cas d’usage critiques et les combinaisons avec les autres techniques.
Pour Self-Ask en profondeur : notre guide Self-Ask détaille le gap de compositionnalité documenté par Press 2022, le scaffolding parsable, 3 familles de problèmes (comparaisons multi-entités, raisonnement temporel, inférences 3-hop), 4 cas d’usage métier et le couplage avec recherche externe (RAG).
Pour Tree-of-Thoughts en profondeur : notre guide Tree-of-Thoughts détaille les 4 composants de l’architecture (décomposition, génération, évaluation, recherche), les stratégies BFS/DFS/beam search, le cas démonstratif du jeu de 24, 4 cas d’usage et l’intégration dans un framework agentique (LangGraph, LangChain).
Pour les utilisateurs IA avancés et les ingénieurs prompt en entreprise, maîtriser ces techniques multi-chain ouvre un champ nouveau : la fiabilisation des sorties critiques. Sans Self-Consistency, vous laissez passer 5 à 10 % d’erreurs sur les raisonnements complexes. Avec, vous descendez à 1 % ou moins. C’est la différence entre un outil qu’on utilise avec contrôle humain systématique et un outil qu’on peut déployer en production sur des tâches à enjeu modéré.
Chez Proactive Academy, nos parcours de prompt engineering avancé intègrent ces techniques par la pratique guidée sur des cas métier réels apportés par les participants. La maîtrise demande typiquement 3 à 5 jours de formation, suivis d’une période d’appropriation par l’usage sur 1 à 3 mois. Pour structurer cette montée en compétence avancée dans vos équipes, découvrez notre parcours de prompt engineering expert en entreprise.
Self-Consistency. C’est la plus simple à mettre en œuvre (vous gardez votre prompt CoT existant et vous l’exécutez plusieurs fois), elle fonctionne sur la majorité des cas, et elle apporte un gain de fiabilité significatif. Self-Ask et Tree-of-Thoughts viennent ensuite sur des cas plus spécifiques.
Oui. Les techniques sont indépendantes du modèle sous-jacent, à condition que le modèle ait la capacité de raisonnement chaîné de base (taille suffisante). Sur GPT-4, Claude 3 et au-delà, Gemini 1.5 et au-delà, Mistral Large, toutes ces techniques fonctionnent. Sur les petits modèles open source, les gains sont plus limités.
Non. Pour 80 % des usages courants, le zero-shot et le few-shot suffisent. Pour 15 % des usages avancés, CoT et Self-Consistency apportent la fiabilité nécessaire. Les 5 % restants (problèmes vraiment complexes, applications critiques) bénéficient de Self-Ask et de ToT. La maîtrise complète n’est utile qu’aux ingénieurs prompt et aux équipes qui construisent des applications IA en production.
Oui, la recherche reste très active. Des techniques plus récentes comme Reflexion (auto-correction par feedback), Graph-of-Thoughts (généralisation de ToT en graphe), et les modèles raisonnants natifs prolongent ces approches. L’état de l’art bouge tous les 6 à 12 mois ; les fondamentaux de ce guide restent valables en 2026 et le seront probablement encore en 2027.
Formule simple par technique : Self-Consistency = N × coût d’un appel CoT (N = 5 à 40), Self-Ask = ~1,5× coût d’un CoT, Tree-of-Thoughts = 50 à 200× coût d’un CoT. À comparer au coût d’une erreur réelle dans votre cas d’usage : si une erreur de diagnostic coûte 500 €, 0,40 € de fiabilisation par Self-Consistency est trivialement rentable.
Pour Self-Consistency et Self-Ask : 2 à 3 jours de formation guidée avec cas réels suffisent pour une maîtrise opérationnelle. Pour Tree-of-Thoughts : 3 à 5 jours plus une période d’appropriation par projet réel sur 1 à 3 mois, parce que l’implémentation se fait dans un framework agentique qui demande des compétences techniques.
Les techniques multi-chain post-CoT ne sont pas un gadget de recherche : elles définissent le terrain de jeu du prompt engineering avancé en 2026. Self-Consistency reste la technique la plus rentable à activer en priorité. Self-Ask brille sur les questions compositionnelles. Tree-of-Thoughts ouvre des cas d’usage inaccessibles par la simple chaîne linéaire, au prix d’une complexité de mise en œuvre supérieure. Pour structurer cette compétence avancée dans vos équipes, découvrez notre parcours de prompt engineering expert en entreprise.



16 juin 2026
Intelligence Artificielle – IA
16 juin 2026
Intelligence Artificielle – IA
16 juin 2026
Intelligence Artificielle – IA
Laisser un commentaire