

Écrit par
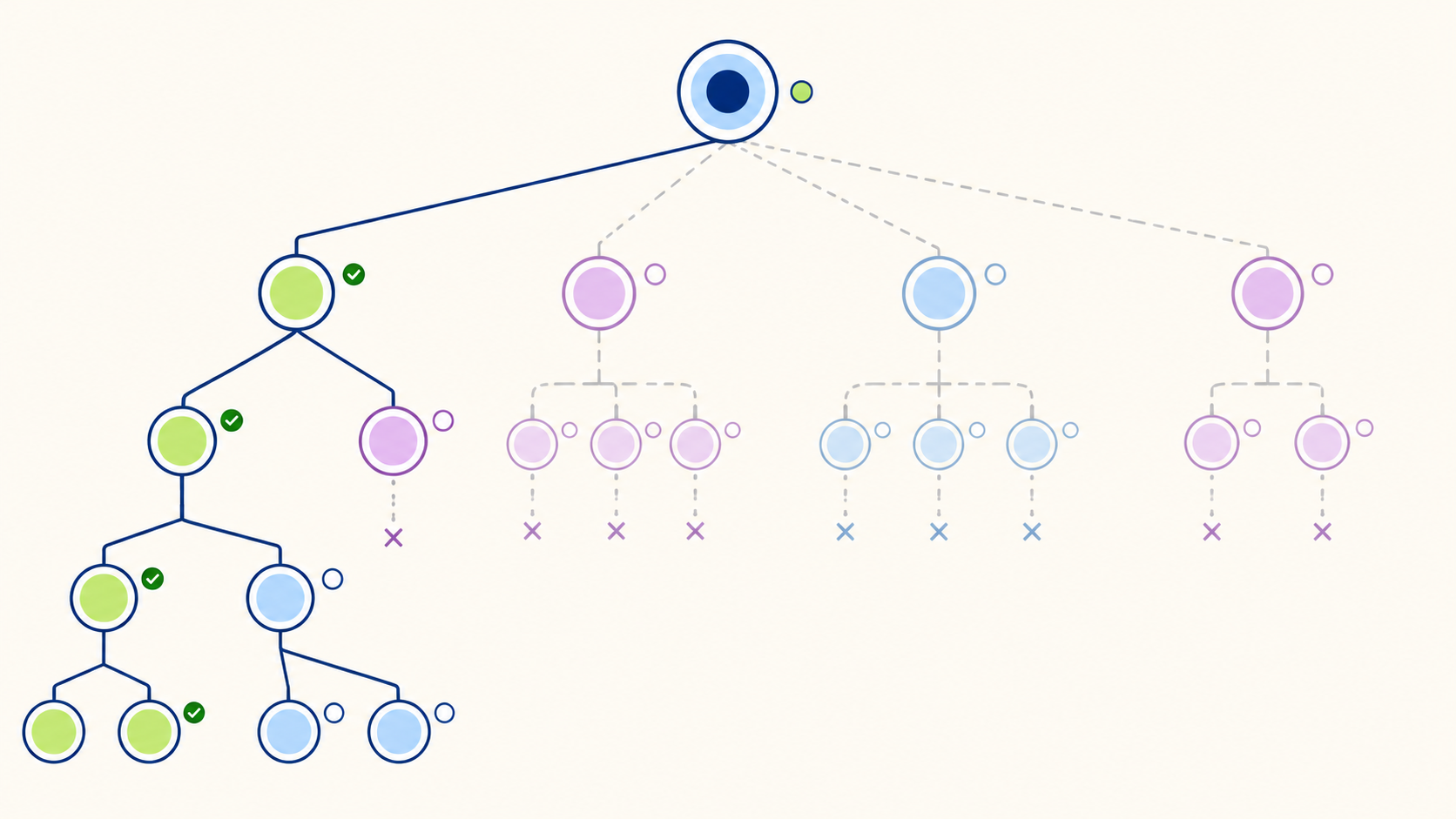
Sur le jeu de 24 (trouver une combinaison d’opérations arithmétiques qui donne 24 à partir de 4 chiffres), GPT-4 avec Chain-of-Thought classique résout 4 % des cas. La même technique encapsulée dans une architecture Tree-of-Thoughts atteint 74 %. L’écart est massif. Publié en 2023 par Shunyu Yao et son équipe à Princeton/Google DeepMind, Tree-of-Thoughts (ToT) est la technique la plus avancée du prompt engineering aujourd’hui : elle traite le raisonnement comme une exploration d’arbre où le modèle génère plusieurs pensées candidates à chaque étape, les évalue, et peut revenir en arrière en cas d’impasse. Ce guide explique le mécanisme, les stratégies de recherche (BFS, DFS), l’intégration dans un framework agentique, et arbitre les cas où ToT change la donne.
Cet article est l’approfondissement Tree-of-Thoughts du mini-cocon des techniques avancées de raisonnement. Pour la vue d’ensemble comparée des 3 architectures multi-chain, voir notre hub des techniques avancées de raisonnement IA. Pour la base CoT sur laquelle ToT s’appuie, voir notre guide Chain-of-Thought (CoT).
En bref
- Tree-of-Thoughts (ToT) traite le raisonnement comme l’exploration d’un arbre où chaque nœud est une « pensée » intermédiaire.
- Origine scientifique : Yao et al. 2023 « Tree of Thoughts: Deliberate Problem Solving with Large Language Models ».
- Mécanisme : à chaque nœud, le modèle génère plusieurs pensées candidates, les évalue, et explore l’arbre selon une stratégie de recherche (BFS, DFS, ou recherche guidée).
- Résultat marquant : sur le jeu de 24, GPT-4 avec CoT classique résout 4 % des cas ; GPT-4 avec ToT atteint 74 % des cas.
- Coût d’inférence : 50× à 200× CoT classique. Réservé aux problèmes vraiment complexes qui justifient le surcoût.
- Implémentation : typiquement dans un script ou framework agentique (LangGraph, LangChain) plutôt qu’à la main dans un prompt utilisateur.
- Pour structurer la maîtrise de ces techniques expertes dans vos équipes, découvrez notre parcours d’architecture de raisonnement IA en entreprise.
Le Chain-of-Thought produit une chaîne linéaire : pensée 1 → pensée 2 → pensée 3 → réponse. Self-Consistency échantillonne plusieurs chaînes parallèles puis vote. Self-Ask décompose en sous-questions séquentielles. Tree-of-Thoughts pousse la logique plus loin encore : il structure le raisonnement comme un arbre où à chaque pensée intermédiaire, le modèle peut explorer plusieurs continuations possibles, les évaluer, et choisir laquelle approfondir.
Cette architecture s’inspire de deux traditions :
Conséquence pratique : sur les problèmes qui demandent vraiment de l’exploration (les chemins possibles sont nombreux, le bon chemin n’est pas évident a priori), ToT débloque ce que CoT ne sait pas faire.
ToT articule quatre composants indépendants. Comprendre chacun est nécessaire pour implémenter la technique.
Le problème global doit être décomposé en pensées intermédiaires suffisamment granulaires pour être évaluées, mais pas trop petites pour rester gérables. Yao et al. donnent des exemples par domaine :
La granularité est un paramètre de conception. Trop fine : l’arbre explose en taille. Trop grosse : on perd le bénéfice de l’exploration.
À chaque nœud de l’arbre, le modèle génère plusieurs pensées candidates pour la suite. Typiquement entre 3 et 8 candidats par nœud. La génération se fait via un prompt qui demande explicitement « plusieurs propositions différentes pour continuer le raisonnement à partir de cet état ».
C’est le composant qui distingue ToT des autres techniques. Pour chaque pensée candidate, le modèle évalue sa qualité selon des critères explicites :
L’évaluation peut être réalisée par le même modèle (auto-évaluation), par un modèle dédié (juge externe), ou par un système hybride. Yao et al. recommandent une note sur une échelle (1-10 ou « sûr / peut-être / impossible ») pour permettre le tri.
Une fois les pensées générées et évaluées, comment explorer l’arbre ? Trois stratégies principales :
Breadth-First Search (BFS) : on explore tous les nœuds d’un niveau avant de descendre. Utile quand on veut comparer plusieurs branches à profondeur égale avant de trancher.
Depth-First Search (DFS) : on plonge sur la branche la plus prometteuse jusqu’à atteindre une feuille (solution ou impasse), puis on remonte (backtracking) pour explorer une autre branche. Utile sur les problèmes où la profondeur est élevée et l’évaluation à mi-parcours fiable.
Recherche guidée par évaluation (beam search) : à chaque niveau, on garde uniquement les k meilleures pensées (selon l’évaluation) et on les développe. Compromis efficace en pratique.
Le jeu de 24 est le benchmark phare des expériences Yao et al. La règle : étant donné 4 chiffres entre 1 et 13, trouver une combinaison d’opérations arithmétiques (+, −, ×, ÷) qui donne exactement 24. Par exemple, avec 4, 5, 6, 10 : une solution est (10 − 4) × (5 − 5/5), mais il faut explorer plusieurs voies avant de trouver.
Sur ce problème :
L’écart entre CoT et ToT est massif. La raison : le jeu de 24 demande vraiment de l’exploration. Le modèle doit essayer plusieurs combinaisons, échouer, revenir en arrière, et tester une autre voie. Sur cette tâche, la chaîne linéaire est structurellement inadaptée, peu importe le nombre d’échantillons. Seule une architecture qui structure l’exploration et permet le backtracking peut résoudre.
Cette observation a une portée générale : plus le problème demande d’exploration et de retour en arrière, plus l’écart entre ToT et CoT se creuse.
Tous les problèmes où l’on cherche une combinaison parmi de nombreuses possibilités, avec contraintes à respecter.
Exemples typiques :
- Trouver une séquence d’opérations qui atteint un objectif
- Résoudre un sudoku ou un puzzle logique
- Composer un menu équilibré sous contraintes nutritionnelles
- Optimiser l’ordonnancement de tâches sous contraintes de précédence
Sur ces problèmes, le CoT classique se perd dès la deuxième ou troisième décision. ToT explore systématiquement et trouve la solution quand elle existe.
Toutes les tâches d’écriture, de design ou de conception qui doivent respecter plusieurs règles simultanément.
Exemples typiques :
- Écrire un scénario qui respecte 5 contraintes narratives, de ton, de durée et de genre
- Concevoir une architecture technique qui respecte des exigences de performance, sécurité, coût, maintenance
- Composer un argumentaire commercial qui répond à un cahier des charges précis
ToT permet de générer plusieurs versions, les évaluer sur les critères imposés, et retenir la meilleure. Cette industrialisation dépasse l’écriture manuelle de prompt.
Tous les diagnostics où la cause racine se trouve dans un espace d’hypothèses étendu avec des tests progressifs pour discriminer.
Exemples typiques :
- Diagnostic technique d’un incident multi-couches (réseau / système / applicatif / base)
- Diagnostic médical différentiel sur un patient avec symptômes ambigus
- Investigation d’un problème de qualité produit avec causes potentielles multiples
ToT structure l’exploration des hypothèses, évalue la probabilité de chaque branche au fil des nouveaux éléments, et concentre l’effort sur les pistes les plus prometteuses.
Tree-of-Thoughts ne s’implémente quasiment jamais à la main dans un prompt utilisateur. La technique demande des dizaines voire des centaines d’appels au modèle orchestrés selon une logique précise. En 2026, l’implémentation se fait dans un script ou un framework agentique.
LangGraph (de l’écosystème LangChain) propose des primitives natives pour implémenter ToT : nœuds, transitions, état partagé, branchements conditionnels, backtracking. C’est aujourd’hui le framework le plus utilisé pour les implémentations ToT en production.
L’écosystème LangChain de base permet d’implémenter ToT mais avec plus de code. Pour les architectes qui veulent un contrôle fin sur chaque appel et chaque évaluation, LangChain reste valable.
Beaucoup d’organisations en production en 2026 utilisent des solutions propriétaires construites sur les API natives des grands modèles (OpenAI, Anthropic, Google). Cette approche donne le maximum de contrôle mais demande plus de développement initial.
Pour le contexte applicatif et l’intégration de ToT dans une architecture d’agents IA, voir notre pilier agents IA et frameworks ainsi que notre guide LangChain LangGraph.
Depuis 2024-2025, les modèles « raisonnants » d’OpenAI (o1, o3), Anthropic (Claude 3.7 et au-delà avec extended thinking) et DeepSeek (R1) ont intégré des mécanismes proches de l’exploration arborescente directement dans l’entraînement et l’inférence. Ces modèles produisent en interne une chaîne de raisonnement longue qui inclut souvent des explorations d’alternatives et des retours en arrière.
Conséquence pratique : sur ces modèles, ToT explicite peut sembler redondant. Mais la maîtrise de l’architecture ToT reste utile en 2026 pour quatre raisons :
ToT + Self-Consistency : à chaque nœud de l’arbre, on peut appliquer Self-Consistency pour évaluer plus robustement la qualité d’une pensée. Coût multiplié, mais gain de fiabilité sur les évaluations critiques. Voir notre guide Self-Consistency en profondeur.
ToT + Self-Ask : sur les problèmes où la décomposition initiale n’est pas évidente, ToT peut générer plusieurs décompositions Self-Ask candidates, les évaluer, et retenir la meilleure pour suite du raisonnement. Voir notre guide Self-Ask en profondeur.
ToT + RAG : à chaque nœud où une information factuelle est nécessaire, on peut intercaler un appel à un système de recherche augmenté. Cette architecture est utilisée par les agents IA les plus avancés en production. Voir notre guide RAG.
Pour produire un argumentaire qui doit respecter 6 contraintes simultanément (durée < 3 minutes, ton conforme à la charte, mention obligatoire d’un argument réglementaire, adaptation au persona, traitement des 3 objections principales, appel à l’action clair), un script ToT génère plusieurs versions candidates à chaque niveau (ouverture, corps, traitement d’objections, conclusion), évalue chaque version sur les 6 critères, et retient la meilleure feuille de l’arbre. Cette industrialisation dépasse l’écriture manuelle.
Pour concevoir une stratégie de déploiement IA en entreprise qui doit respecter des contraintes de budget, de calendrier, de gouvernance, de conformité (AI Act), de gestion du changement, ToT explore plusieurs scénarios candidats, évalue chaque scénario sur les contraintes, et retient le scénario le plus prometteur. Sortie : un plan structuré avec étapes, jalons et critères de succès.
Pour composer un parcours de formation personnalisé pour un apprenant donné, en respectant des contraintes de niveau initial, de disponibilité, d’objectifs métiers, de modalités préférées, ToT explore plusieurs compositions candidates (séquencement des modules, durées, format présentiel/distanciel, évaluations), évalue chaque composition sur les critères, et retient celle qui maximise l’adéquation. Cette technique combine avec les méthodologies de notre guide d’évaluation des apprenants avec l’IA.
Pour concevoir une architecture technique (microservices, base de données, infrastructure) qui doit respecter des exigences de performance, sécurité, coût, maintenabilité, ToT explore plusieurs designs candidats à chaque couche, évalue chaque design sur les exigences, et retient l’ensemble cohérent qui maximise la satisfaction globale. Ce type d’usage est typique des assistants d’architecture en production aujourd’hui.
Limite 1 : le coût d’inférence multiplié par 50 à 200. ToT n’est rentable que sur les problèmes où le gain de qualité justifie largement ce surcoût. Pour les usages courants, gardez CoT ou Self-Consistency.
Limite 2 : la complexité d’implémentation. Contrairement à Self-Consistency (simple à mettre en place avec un loop), ToT demande une architecture de code structurée : génération de candidats, évaluation, traversal de l’arbre, backtracking, état partagé. Comptez plusieurs jours pour une première implémentation propre.
Limite 3 : la qualité de l’évaluation est critique. Si l’évaluation des pensées est mauvaise (auto-évaluation trop optimiste, critères mal définis), l’arbre se développe dans des directions improductives et le coût explose sans bénéfice. La qualité de l’évaluateur est souvent le facteur limitant en pratique.
Limite 4 : l’explosion combinatoire sur les problèmes profonds. Sur les problèmes où la profondeur d’exploration dépasse 5-7 niveaux, l’arbre devient ingérable. Solutions : élagage agressif (beam search étroit), évaluation très stricte, ou décomposition en sous-problèmes.
Pour les architectes d’agents IA et les équipes recherche IA, Tree-of-Thoughts ouvre des cas d’usage que les techniques single-chain et multi-chain plus simples ne savent pas couvrir. Sur les problèmes vraiment complexes (combinatoires, génératifs sous contraintes multiples, diagnostics avec espace d’hypothèses large), ToT est aujourd’hui l’état de l’art accessible.
Chez Proactive Academy, nos parcours experts intègrent Tree-of-Thoughts dans la pratique architecturale d’agents IA avancés. La technique demande typiquement 3 à 5 jours de formation pour acquérir les fondamentaux, suivis d’une période d’appropriation par projet réel sur 1 à 3 mois. Pour structurer cette montée en compétence experte dans vos équipes, découvrez notre parcours d’architecture de raisonnement IA en entreprise.
ToT est utilisable en entreprise, mais quasiment toujours via un framework agentique (LangGraph, LangChain, ou solution propriétaire) plutôt qu’à la main dans un prompt utilisateur. Pour une équipe entreprise qui veut activer ToT, le bon point d’entrée est un framework agentique avec une équipe technique formée. Voir nos articles sur les agents IA et frameworks multi-agents.
Trois familles : (1) problèmes combinatoires (puzzles, optimisations, planifications), (2) génération créative sous contraintes multiples, (3) diagnostics complexes avec espace d’hypothèses large. Sur les usages courants (rédiger, résumer, classifier), ToT est sur-armé.
Règle pratique : commencez par beam search avec une largeur 3 à 5. C’est le compromis efficace en pratique. Utilisez BFS pour comparer plusieurs branches à profondeur égale. Utilisez DFS quand la profondeur est élevée (> 5 niveaux) et l’évaluation à mi-parcours fiable.
Règle pratique : 3 à 5 candidats par nœud. En dessous, vous perdez le bénéfice de l’exploration. Au-dessus, le coût explose sans gain proportionnel. Ajustez selon le coût d’un appel modèle et le budget total alloué au problème.
Oui, mais le bénéfice marginal est réduit parce que ces modèles font déjà une exploration interne. Sur ces modèles, ToT externe reste utile pour le contrôle, l’audit, et l’intégration d’outils. Sur les modèles standard, ToT externe apporte une valeur plus importante.
L’auto-évaluation suffit dans la plupart des cas. Pour les usages critiques où l’évaluation doit être stricte, un modèle dédié à l’évaluation (potentiellement plus petit et plus rapide) peut être préférable. Le coût marginal d’un évaluateur dédié est modeste, le gain de qualité peut être significatif.
Trois leviers : (1) élagage agressif (beam search étroit, largeur 2-3 seulement), (2) évaluation stricte qui élimine rapidement les branches peu prometteuses, (3) décomposition du problème en sous-problèmes plus petits traités séquentiellement.
Oui, la recherche reste active. Des extensions comme Graph-of-Thoughts (généralisation de ToT en graphe avec re-fusion de branches), Reflexion (auto-correction par feedback itératif), et les agents multi-modèles spécialisés prolongent cette ligne. ToT reste cependant l’architecture de référence accessible aujourd’hui.
Tree-of-Thoughts est la technique la plus avancée du prompt engineering en 2026. Sur les problèmes vraiment complexes, l’écart avec les techniques single-chain et même avec Self-Consistency est massif. Le surcoût d’inférence et la complexité d’implémentation la réservent à des usages où le retour sur investissement est clair. Pour la vue comparative avec les autres techniques multi-chain (Self-Consistency, Self-Ask), voir notre hub des techniques avancées de raisonnement IA. Pour structurer cette compétence experte dans vos équipes, découvrez notre parcours d’architecture de raisonnement IA en entreprise.



16 juin 2026
Intelligence Artificielle – IA
16 juin 2026
Intelligence Artificielle – IA
16 juin 2026
Intelligence Artificielle – IA
Laisser un commentaire